 DSLR & Mirrorless
DSLR & Mirrorless  3D Camera
3D Camera  Drone & Action camera
Drone & Action camera 


Perceptual AI-based Metrics (AZ Mate) Add-on
Detail Preservation Evaluation on realistic scene
DXOMARK developed machine learning-based methods that estimate the perceptual image quality perceived by a human expert when evaluating pictures of known content. The detail preservation metric quantifies the capacity of a camera to produce sharp images precisely and pleasantly based on a trained dataset of the scene.
Key Highlights
- Photo & Video measurements
- Detail Preservation Metric
- Perceptual Noise Quality Metric
Related Links and Documents
Why “Perceptual”?
The quality of an image can be evaluated on several attributes: target exposure, dynamic range, color (saturation and white balance), texture, noise and different artifacts. For portrait images, the main focus is to evaluate the rendering quality of the face. On this matter, characteristics like skin tone, depth estimation, texture details and skin smoothness are mostly of interest, but these attributes should be measured in a way that reflects the human perception. Here, we focus on evaluating camera capabilities to preserve fine texture details on the face. To ensure a precise interpretation of the comparisons and the repeatability of the metric, we define static portrait scenes by using a Realistic Mannequin setup in a controlled environment. Since it provides consistent visual content, environment variance and bias are eliminated, the associating score change can be due to the camera’s capability alone.
Why “AI-based Metrics”?
Traditional MTF-based methods are originally designed for conventional optical systems that can be modeled as linear and shift-invariant. Consequently, non-linear functions in the camera processing pipeline, such as multi-images fusion or deep learning-based image enhancement, may lead to inaccurate quality evaluation. Hence, DXOMARK developed learning-based methods that aim at reproducing the level of detail preservation perceived by human experts evaluating pictures of a known content.
Moreover, on portrait scenes, cameras nowadays are capable of automatically detecting faces and apply adapted image processing pipelines. This context motivated DXOMARK researchers to develop specific metrics on realistic 3D faces to evaluate a camera’s behavior on a typical portrait scene use case. The realistic mannequins can be placed under different lighting conditions and slight pose differences (i.e. rotations) to multiply the possible tests.
DXOMARK Chart
The DMC chart is designed to represent texture patterns that can be found in natural scenes which makes it ideal for texture and noise quality assessment. The implemented metrics treat texture and noise evaluation as a regression problem. This regression is performed through a deep convolutional network that returns a real value that strongly correlates with a subjective quality judgment after training on a large image quality labeled dataset. For each measure, a set of representative predefined regions of interest are selected. The metric automatically extracts these regions of interest and gives a comprehensive metric for each crop, that allows to rank images according to their level of quality.


Realistic Mannequin
The Realistic Mannequin (RM) Detail Preservation Metric is a machine learning-based method that assesses the level of perceived texture quality on a face in a controlled portrait setup environment, by quantifying the capacity of a camera to produce sharp images precisely and pleasantly based on a mental representation of the scene. The presence of ringing and over-sharpening is penalized, as well as artifacts such as Moiré patterns (demosaicing artifacts) or over-smoothing in portraits (”waxy effect” on skin surfaces). As for the DMC chart, the RM Detail Preservation Metric also focuses on regions of interest of the faces such as the eyes or the beards where high texture quality is challenging.

DXOMARK expert dataset and annotation details
The data set is composed of hundreds of images, each annotated with a detail preservation or noise reproduction quality depending on the task. These images were acquired under the following conditions: 1 Lux H, 5 Lux A, 20 Lux A, 100 Lux A, 300 Lux TL84 and 1000 Lux D65. The cameras used had sensors with resolutions between 0.46 and 60 mega pixels.
Annotations were conducted in a controlled environment with fixed viewing conditions:
- The monitors are calibrated with a D65 white point with luminance ≥ 75cd/m2 with no direct illumination of the screen and a background illumination with a lighting panel set to D65 / 15% to reduce eye stress.
- Experts rigorous viewing condition are set to a fixed 90cm distance from the screen.
The pairwise annotations allow the construction of psychophysical image quality scales in Just Objectionable Difference (JOD) scale units. The JOD is a measure of impairment, meaning that it measures how much distortion there is in an image with respect to a mental representation of the ’ideal image’. Statistically, a JOD measures the probability of an image A being qualified as ”of better quality” than image B. A difference of 1 JOD between two values means that 75% people that evaluated the pair chose A over B. The obtained JOD values, for each scene, are relative to their own scale.
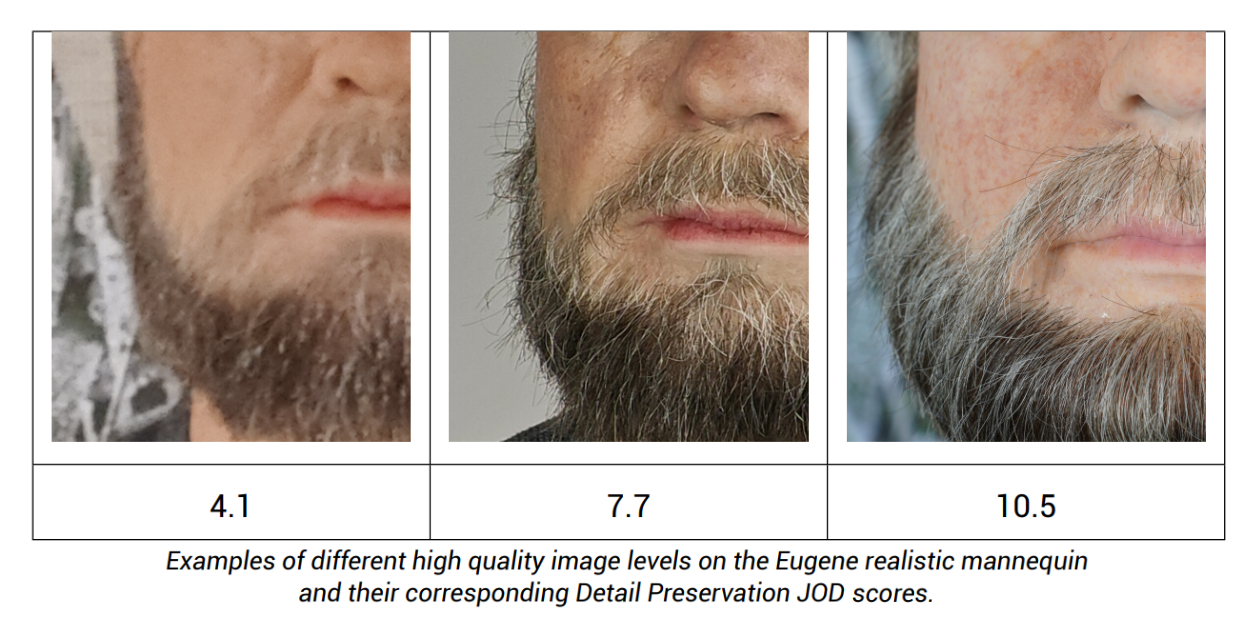
DMC data set. The images were annotated using a stack system by a panel of experts in image quality. The annotators were asked to correctly classify the images to be evaluated among a stack of references by considering the level of perceived details. The rankings of all annotators were then accumulated into a comparison matrix from which one can infer quality scores. The outputs from the pairwise comparison are then scaled into JODs units. Examples can be found below, with higher score meaning higher level of details.
RM Dataset. The Detail Preservation Metric is represented in JOD units. The images have been annotated by a panel of experts in image quality using pairwise comparisons, by choosing the image that has the best detail preservation among the 2.
DXOMARK AI-based Metrics
These metrics are implemented as deep convolutional network with the aim of returning a image quality score (texture or noise) that strongly correlate with the subjective quality judgment. The model backbone are ResNet-18, and the extracted features are fed to fully connected blocks (FC). To ensure a reliable metric, we run the convolutional network on a specific region of interest (ROI) within the targeted image. The final output is a single float value, representing the final quality value of the input image.

| Product Type | Software |
|---|---|
| Image Quality Metric | 3A (Exposure, Focus & White balance), Color, Noise & Tone curves, Real life scenes, Resolution, Sharpness & Texture |